
Singly Linked List

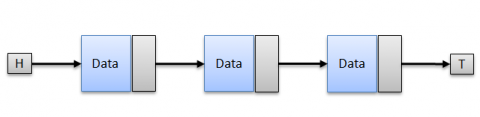
Singly Linked List is the most basic of Linked List implementations. It's a one-way list of Nodes from Head to Tail!
To implement a Singly Linked List, we must first create a Node structure (or a class) that will hold the data and the node reference to the next Node.
In C++ we do this by declaring the following SL_Node structure. We will be using templates so we can handle different kinds of data in one single program.
template<class T> struct SL_Node { T data; SL_Node* next; };
The next part is to come up with a class that we'll call SL to declare the Singly Linked List operations.
template<class T> class SL { private: SL_Node<T>* head; SL_Node<T>* tail; #ifdef ALLOW_SIZE int size; #endif public: SL(); ~SL(); inline SL_Node<T>* insertAfter(SL_Node<T>* node, T data); inline void deleteAfter(SL_Node<T>* node); inline SL_Node<T>* attachAfter(SL_Node<T>* node, SL_Node<T>* detachedNode, T data); inline SL_Node<T>* detachAfter(SL_Node<T>* node); inline SL_Node<T>* searchAfter(SL_Node<T>* node, T data); void display(); inline SL_Node<T>* getHead() const { return head; } inline SL_Node<T>* getTail() const { return tail; } #ifdef ALLOW_SIZE inline int getSize() const { return size; } #endif };
Note that the method getSize is within the #ifdef ALLOW_SIZE directive, which if not defined will not be part of the compilation. The getSize() method and the size variable are just meant for debugging purposes and will not be used in the actual implementation of the Singly List to get that extra precious speed in the insertion and deletion of Nodes.
Our implementation of Singly List consists of the following operations:
- Initialization (Constructor)
The initialization is where you create Nodes for the Head and Tail, set the next Node Reference of the Head to Tail, and the Tail to itself. The initialization of the Singly Linked List is done thru the constructor of our Singly Linked List Class (SL)
template<class T> SL<T>::SL() : head(new SL_Node<T>), tail(new SL_Node<T>) { head->next = tail; tail->next = tail; #ifdef ALLOW_SIZE size = 0; #endif }
- Destructor
The basic idea of a destructor is to remove all allocated Nodes from memory. You do this by walking the list from Head until you reach the Tail, and then deleting each Node as you encounter. The final step is deleting the Tail.
template<class T> SL<T>::~SL() { SL_Node<T>* tmp; do { tmp = head; head = head->next; delete tmp; } while (head != tail); delete tail; }
- Insert After (insertAfter)
This method grows the Singly Linked List by one (1) Node and takes two (2) parameters: The Node Reference before the new Node to be added and the data.
It is important to note that this method assumes you're not adding a new node after the tail. As it may have undesired and unpredictable results. It is recommended that validation be handled outside this function if speed is what you sought after.
It is also advisable to avoid any conditional statements inside this method especially if this method is inside a loop. If you've already browsed the internet for a similar solution, you'll notice that the Head and Tail Nodes are initially set to NULL and that a special condition is tested inside the Insert Operation of the list whether it's set to NULL or not.
if (head == NULL) { head = new SL_Node<T>; tail = head; tail->next = tail; } else { tmp = new SL_Node<T>; tmp->next = node->next; node->next = tmp; }
This can be avoided by dedicating a Node for the Head and Tail giving you that precious speed.
Our implementation of the insertAfter method simply allocates a new Node to a temporary variable and sets its data. Then set the next Node Reference to the next of node. The final step is assigning the next Node of the node to the temporary Node variable.
SL_Node<T>* SL<T>::insertAfter(SL_Node<T>* node, T data) { // // Method assumes you're not adding to the tail // // Validation should be handled outside this function // if speed is what you sought after // // Returns the newly added node // SL_Node<T>* tmp = new SL_Node<T>; tmp->data = data; tmp->next = node->next; node->next = tmp; #ifdef ALLOW_SIZE ++size; #endif return tmp; }
- Delete After (deleteAfter)
This method reduces the list by one (1) node and it takes the Node Reference before the actual Node to be deleted parameter.
The procedure to delete simply creates a temporary variable to hold a reference to the node to be deleted, in particular, the node->next. The next Node Reference of the node is then set to the next Node Reference of the temporary variable. And finally, the temporary variable is deleted.
template<class T> void SL<T>::deleteAfter(SL_Node<T>* node) { // // Method assumes you're not deleting the tail. // // Validation and delete should be handled outside this function // if speed is what you sought after // // Returns the Node to be kept somewhere // SL_Node<T>* tmp = node->next; node->next = tmp->next; #ifdef ALLOW_SIZE --size; #endif delete tmp; }
Just like the insertAfter, it is important to note that this method assumes you're not deleting after the tail. As it may have undesired and unpredictable results.
We've introduced two (2) methods below (Attach After and Detach After) if protection against deallocation is necessary. These methods can be used in a separate list of detached Nodes, which can, later on, be attached back to the Singly Linked List you are working on.
- Attach After (attachAfter)
This method is similar to insertAfter, but instead of allocating a new Node, it attaches a Node from the Detached List and overriding its data.
template<class T> SL_Node<T>* SL<T>::attachAfter(SL_Node<T>* node, SL_Node<T>* detachedNode, T data) { // // Method assumes you're not adding to the tail // // Validation should be handled outside this function // if speed is what you sought after // // Returns the newly added node // detachedNode->data = data; detachedNode->next = node->next; node->next = detachedNode; #ifdef ALLOW_SIZE ++size; #endif return detachedNode; }
- Detach After (detachAfter)
The key difference of detachAfter from deleteAfter is that it doesn't deallocate the Node giving you that tail deletion protection and speed. It also returns the Node Reference to the detached Node, which you can then use to attach to your List of Detached Nodes.
template<class T> SL_Node<T>* SL<T>::detachAfter(SL_Node<T>* node) { // // Method assumes you're not detaching the tail. // // Validation and delete should be handled outside this function // if speed is what you sought after // // Returns the Node to be kept somewhere // SL_Node<T>* tmp = node->next; node->next = tmp->next; #ifdef ALLOW_SIZE --size; #endif return tmp; }
- Display
This method just prints the data to the screen, assuming the data type of the Singly Linked List is printable.
The display process is a walk the list after the Head until it encounters the Tail. For each iteration in the loop, the data is printed to the console.
template<class T> void SL<T>::display() { // // Simply displays the output assuming T can be printed in std::cout // SL_Node<T>* tmp = head->next; while (tmp != tail) { std::cout << tmp->data << "\n"; tmp = tmp->next; } #ifdef ALLOW_SIZE std::cout << "\nNode Size: " << sizeof(*head) << "\n"; std::cout << "Node Count: " << size << "\n"; std::cout << "Node Count including Head+Tail: " << size + 2 << "\n"; std::cout << "Memory Occupied: " << (size + 2) * sizeof(*head) << "\n"; #endif }
- Search After (searchAfter)
Search After (searchAfter) is a walk the list method starting after the Node Reference passed until it finds the data parameter or until it reaches the Tail Node. This method returns the Node Reference of the Node where its data matches that of the parameter.
template<class T> SL_Node<T>* SL<T>::searchAfter(SL_Node<T>* node, T data) { // // Simply displays the output assuming T can be printed in std::cout // SL_Node<T>* tmp = node->next; while (tmp != tail) { if (data == tmp->data) { break; } tmp = tmp->next; } return tmp; }
searchAfter can be used inside a loop to find all occurrences of data.
tmp = singly->getHead(); count = 0; while (tmp != singly->getTail()) { tmp = singly->searchAfter(tmp, 30); ++count; } std::cout << "\n\nFound " << count << " occurence(s) of #30\n";
- Swap After (swapAfter)
With all the necessary operations defined, I'll leave it up to the reader to implement the Swap After Operation, wherein it takes two parameters: The Node References before the actual Nodes to be swapped.
These are just the basic Singly List Operations, you can add your own methods as you see fit in your applications. You may experiment and download the source code below.
