
Linked List

Linked List is a set of Nodes where a Node is a data and a reference to the next node. The reference to the next node is an item required in the structure of a Linked List because it's not organized sequentially in memory like the Array, although it can also be represented using Arrays as you will see in our implementation of Singly List.
Accessing an element:
A Linked List is normally accessed thru its Head Node until you reach the key data you are looking for, unlike the Array where you randomly access its elements by indicating the index. So if you have N elements and k is an element between the Head Node and N, then you have to traverse 1 to k Nodes unless you're not starting with the Head Node + 1. Clearly, the Array has a speed advantage over the Linked List.
Advantages of Linked Lists over Arrays:
Compared to an Array, a Linked List has a space advantage. It's quite useful in scenarios where you have to limit the use of memory to perform the necessary operations of your applications. Linked List also has the upper hand in terms of rearranging (insertion and deletion) its nodes over Arrays but at the expense constant speed regardless of the size. This will become apparent to the reader as we see the different implementations of Linked Lists and some practical examples.
Parts of a Linked List:
Linked List consists mainly of three (3) parts:
- Node
The Node represents every element in the Linked List. It consists of the data and a reference to the next Node. It's normally represented as a structure with the following attributes:
- struct Node
- {
- T data;
- Node* next;
- }
Where T can be any data type or normally represented by template in C++. The *next pointer is a Node Reference to the next Node.
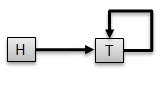
- Head
The Head is a Node that marks the starting point of a Linked List. Searching in a Linked List starts from the Head to the key data you are searching for unless a Node Reference is set to mark the starting point of the search. The data of the head is normally set to NULL.
- Tail
The Tail is also a Node that marks the endpoint of a Linked List and is pointed to itself. Although in a Circular Linked List, the Tail can be omitted and can be represented by the Head. The data of the tail is normally set to NULL.
If you searched the internet, most implementations of the Head and Tail are initially set to NULL and that they are just mere Node References or pointers to the next Node giving you an extra advantage in space. However, this extra space is insignificant to the overall performance of your program and an additional condition is required every time you perform an insert operation, which could hinder the speed of your application if it's inside a loop.
Linked List Operations:
Linked List consists of the following basic operations. You can add more operations as you see fit. The actual program implementation of different Linked List Types can be found on the links below.
- Initialize
Initialization is the very first step in Linked List operations. This is where you create Nodes for the Head and Tail. This is also where you reference head to tail, and tail to itself. Initialization is normally done in the class constructor for OOP implementations of list such as C++.
- Insert After
The Insert After (insertAfter) operation grows the Linked List between the Head and Tail by one (1) Node. insertAfter takes two (2) parameters - The Node Reference before the new Node to be inserted and the Data. So if you want to insert after the head you just do insertAfter(head, data).
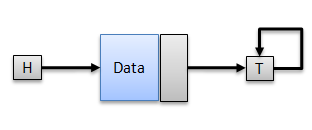
Important: The programmer must make sure not to make the mistake of inserting after the tail i.e. insertAfter(tail, data) to prevent unpredicted results. The figure below illustrates what happens when you try to do this.
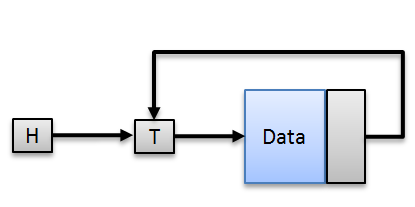
The validation has to be done outside the implementation of insertAfter to prevent unnecessary conditional statements within the function, especially if efficiency in speed is what you sought after.
- Delete After
DeleteAfter (deleteAfter) decreases the set of Nodes by one (1) and deletes the Node after the Node Reference parameter specified. And just like insertAfter, the programmer must make sure not to make the mistake of deleting the tail i.e. deleteAfter(noderef, data), where noderef.next is the Tail.
- Search After
The Search After (searchAfter) is a walk the list function from the node after the Head or from a certain node reference to the key data you are looking for.
The Search function takes two (2) parameters. The Node Reference before the search and the data to be searched. For each Node, searchAfter will compare each and every one of the data if it matches the parameter to be searched. searchAfter returns the Node Reference of the matching Node. The programmer can use searchAfter in a loop multiple times and use the last returned Node Reference as a starting point of the search until it reaches the Tail Node to find all data that matches the criterion.
-
Swap After
Now that we know how Node insertion and deletion work, we can combine these two operations together with search to swap or rearrange two Nodes together. Swap After (swapAfter) takes two (2) parameters, which are the Node References before the Node to be swapped.
-
Display
The Display operation is just for debugging purposes to show the list of Nodes between Head (or any Node Reference) and Tail.
The following are common variations and implementations of Linked List:
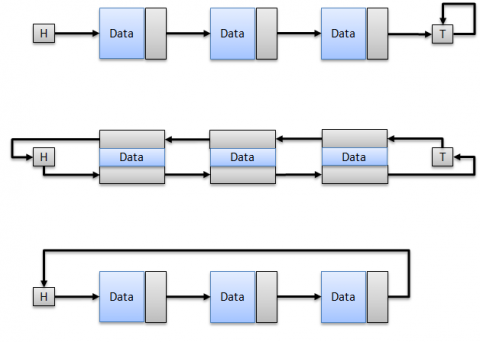
- Singly Linked List
The most basic of all the Linked List, the description above exactly fits the implementation of this type.
- Singly Linked List implemented using an Array
An optimized for speed Singly Linked List implemented using Array. You may prefer to use this over the Regular Singly Linked List if your application requires a Singly Linked List implementation and you prefer speed over storage.
- Doubly Linked List
It's a Linked List that works backward/forward when searching, inserting, and deleting a Node. One thing to take note of when implementing this type is there's an extra overhead to store the previous Node Reference.
- Circular Linked List
Another popular and very useful type of list, wherein the last Node is referenced to the first Node (or the Head for convenience). One application of the circular list are variants of the Josephus Problem.
In the real world, you'll seldom encounter problems requiring List, Trees, Stacks, and Queues because most problems can be solved using variables and arrays. However, it is important and I recommend that you understand the applications and implementations of these elementary data structures to help you better optimize your code and develop better frameworks.
